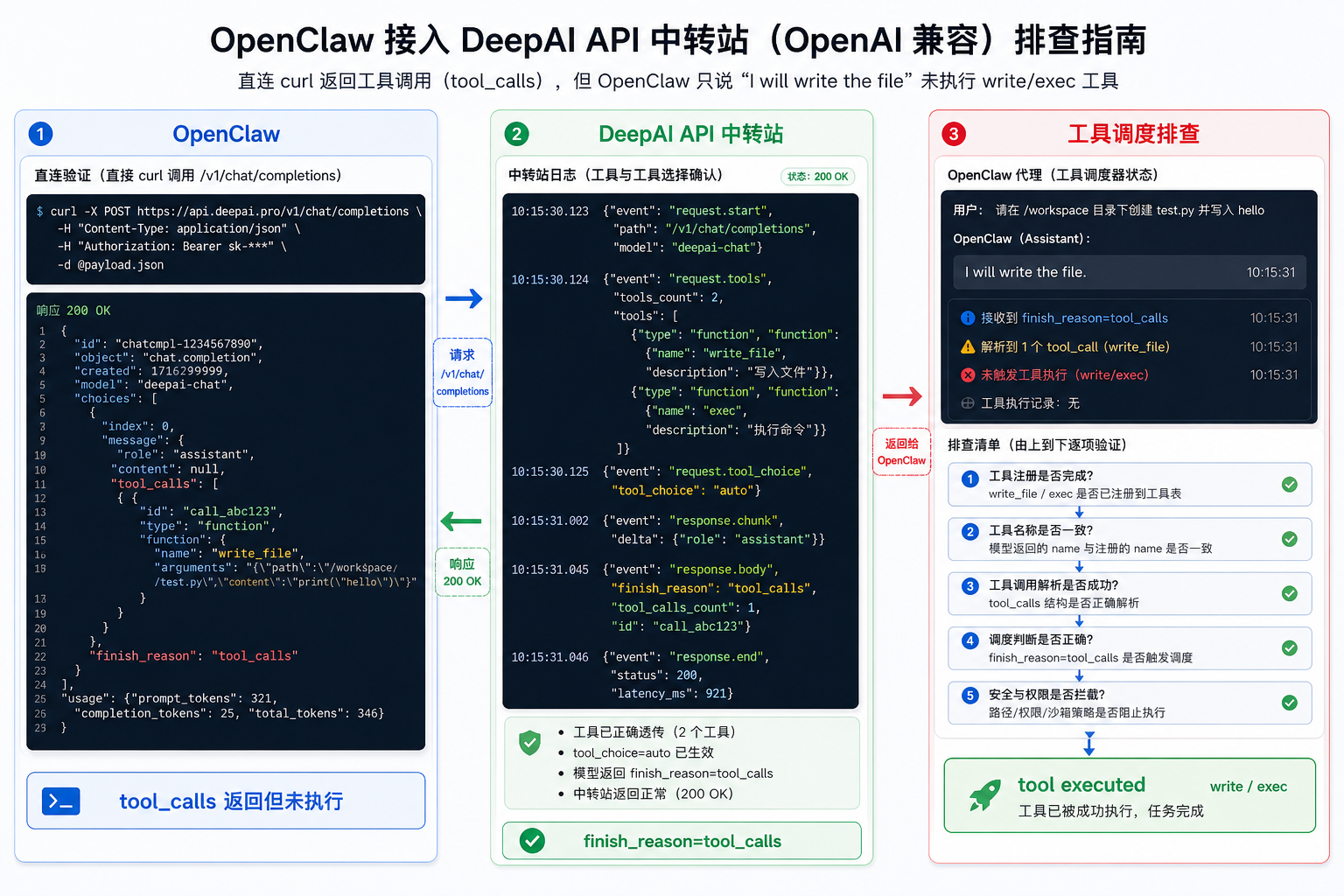
Dify 的知识库功能看起来只是“上传文档、生成向量、检索召回”,但真正跑起来会经过文件解析、分段、Embedding、向量库写入、LLM 辅助处理和 Worker 异步任务。接入 DeepAI API 中转站 或自定义 OpenAI-compatible Embedding Provider 时,如果手动 API 测试成功,但知识库处理后为空,就要按流水线逐层排查。
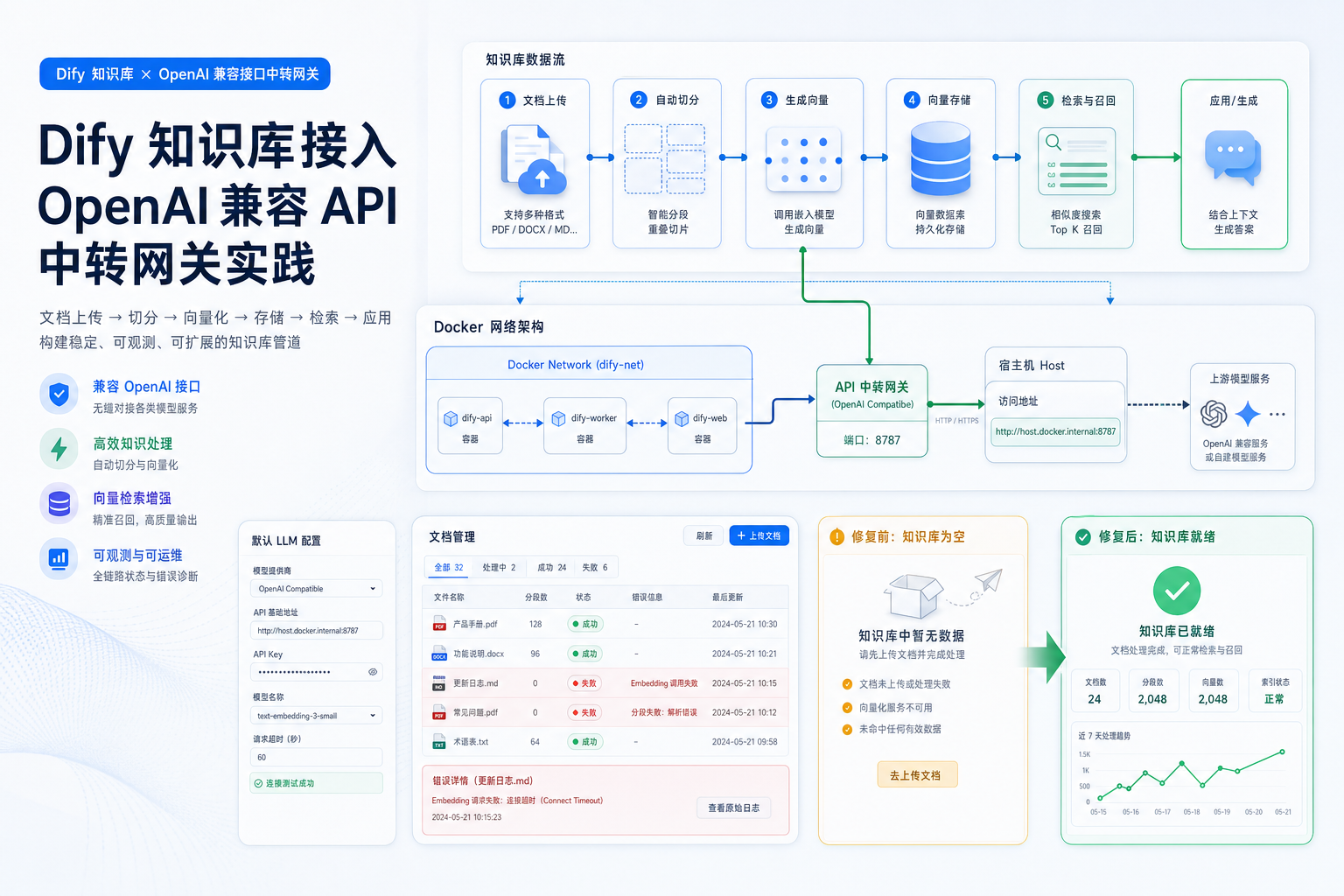
GitHub Issue 背景:Embedding API 能通,但知识库没有 chunks
Dify GitHub 仓库中有一个已关闭的 Issue:用户在自托管 Docker 版 Dify 1.13.0 中,把一个带腾讯云签名协议的 Embedding 服务封装成 OpenAI-compatible 代理,手动调用 /v1/embeddings 能返回标准 JSON,但 Dify 知识库上传文件后结果为空,像是没有写入任何 chunks。
最终排查思路很典型:问题不一定在 Embedding 响应格式,还可能是缺少默认 LLM、Docker 容器访问不到 localhost、分段长度校验、Worker 日志里有隐藏错误,或者 documents 表里的 error 字段没有被前端直接展示。
DeepAI API 中转站的 Embedding 配置思路
如果 Dify 使用 DeepAI API 中转站提供的 OpenAI-compatible Embedding 模型,Base URL 通常填写:
https://api.deepai.wang/v1
然后在 Dify 模型供应商里分别配置 LLM 模型和 Embedding 模型。不要只配置 Embedding:某些知识库模式,例如 QA 分段、层级索引或自动处理流程,仍然需要 workspace 默认 LLM 参与辅助处理。
第一步:确认 Embedding API 响应格式
OpenAI-compatible Embedding 响应至少应包含 data[].embedding、index、model 和 usage 信息。一个简化响应类似:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [0.01, 0.02, 0.03]
}
],
"model": "your-embedding-model",
"usage": {
"prompt_tokens": 12,
"total_tokens": 12
}
}
如果手动 curl 能返回这个结构,只能说明“代理接口基本可用”。它还不能证明 Dify Worker、知识库任务、向量库写入和默认模型配置都正常。
第二步:Docker 里不要用 localhost 指向宿主机服务
Issue 中的代理地址是 http://localhost:8000。在 Docker 自托管 Dify 里,这很容易出问题:容器里的 localhost 指的是容器自己,不是宿主机。如果你的 Embedding 代理跑在宿主机上,Dify 容器可能根本访问不到。
- Docker Desktop 可尝试
http://host.docker.internal:8000/v1。 - Linux Docker 可尝试宿主机网桥地址,例如
http://172.17.0.1:8000/v1。 - 更稳的做法是把代理服务也放进同一个 docker compose 网络,用 service name 访问。
第三步:配置默认 LLM 模型
Dify 知识库并不总是只调用 Embedding。某些分段、QA 生成、层级索引或自动处理模式会依赖 LLM。如果 workspace 没有配置默认 LLM,流程可能在调用 Embedding 之前就中断,前端看起来像“知识库为空”。
建议在 Settings → Model Providers 中同时确认:
- 默认 LLM 模型已配置并可通过凭据验证。
- Embedding 模型已配置并可被知识库选择。
- 两类模型都指向 DeepAI API 中转站或你明确的代理 endpoint。
第四步:降低分段长度做最小化测试
如果大文档处理后为空,先不要直接用默认长分段。建议新建一个测试知识库,把分段长度降到 128 到 256 字符,上传一个很短的 txt 文件,只包含几段普通文本。这样可以排除文件解析、分段过长、模型 token 限制和向量写入的干扰。
最小化测试通过后,再逐步恢复 PDF、DOCX、长文本、QA 分段和层级索引。
第五步:查 documents 表和 worker 日志
知识库前端有时只显示“处理完成”或“为空”,但真实错误在数据库和 Worker 日志里。可以检查 documents 表:
SELECT id, name, indexing_status, error FROM documents WHERE dataset_id = '<your_kb_id>' ORDER BY created_at DESC;
同时开启调试日志:
DEBUG=true LOG_LEVEL=DEBUG docker compose logs -f worker
如果 Worker 日志里出现连接超时、模型不存在、Embedding 维度不一致、向量库写入失败,就能直接定位。
DeepAI API 中转站后台应该看什么
- 请求是否到达:如果后台没有记录,先查 Docker 网络和 Base URL。
- 模型是否正确:Embedding 请求不要误发到聊天模型。
- 状态码:401 看 Key,404 看路径和模型 ID,429 看额度和频率。
- 响应耗时:长文档可能触发超时,需要分批或降低分段长度。
- 用量记录:确认 Embedding 请求确实产生调用日志,便于成本追踪。
生产建议:LLM 和 Embedding 分开管理
Dify RAG 场景里,LLM 和 Embedding 的职责不同,建议在 DeepAI API 中转站里分开做权限和日志。比如给知识库 Embedding 单独一个 Key,给对话生成模型另一个 Key。这样当知识库处理为空、成本异常或召回效果下降时,可以更快定位是哪类模型出了问题。
参考资料
- Dify GitHub 仓库
- Dify Issue #33709:Custom OpenAI-Compatible Embedding Provider Returns Empty Results
- Dify OpenAI-Compatible 404、401 与工具调用排查
- DeepAI API 中转站教程导航
总结
Dify 接入 DeepAI API 中转站做知识库时,Embedding API 手动测试成功只是第一步。知识库为空时,要同时检查默认 LLM、Docker 网络、分段长度、Worker 日志、documents 表 error 字段和 DeepAI 后台请求记录。把 RAG 流水线拆开看,才能判断问题到底是 API 中转站、Embedding 代理、Dify 配置,还是向量库写入环节。