Dify 接入 DeepAI API 中转站 时,很多团队会先用 OpenAI-API-compatible Provider 添加模型,再把它用于聊天、Agent、工作流和 RAG。普通模型通常只要 Base URL、API Key、模型 ID 正确就能跑通;但遇到 o1、GPT-5 或其他 reasoning 模型时,一个常见报错是:Unsupported parameter: 'max_tokens' is not supported with this model. Use 'max_completion_tokens' instead.
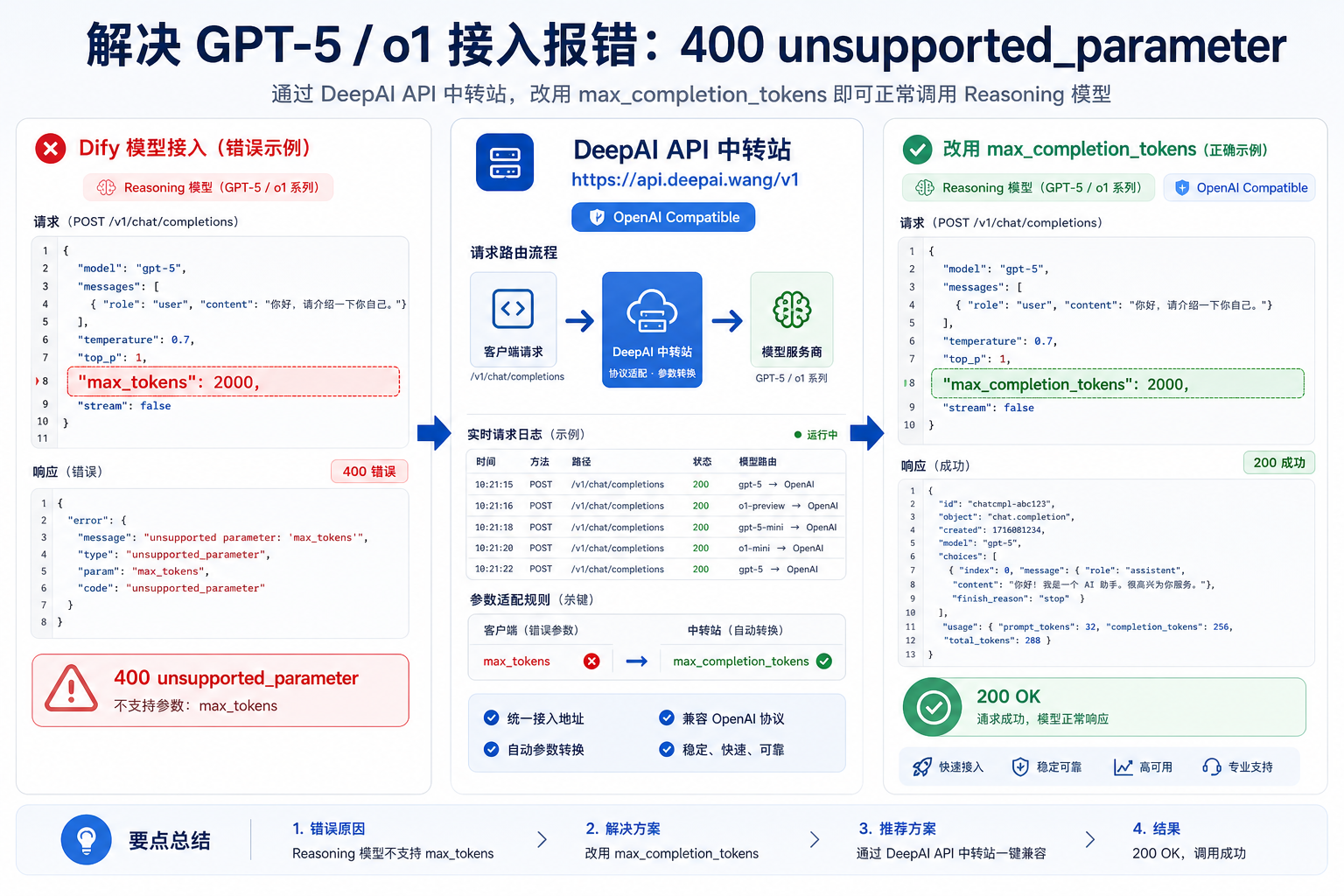
max_tokens 套给所有 OpenAI-compatible 后端。问题背景:模型还没保存就校验失败
这个问题最早可以在 Dify Issue #10348 里看到:用户在 Dify 0.11.0 自托管 Docker 环境中使用 OpenAI o1 模型,设置 maximum tokens 后直接返回 400,错误提示要求使用 max_completion_tokens。后来在 Dify Official Plugins Issue #1845 中,用户在 Dify 1.9.1 里添加 gpt-5 到 OpenAI-API-compatible Provider,也在凭据校验阶段遇到同样错误。
这类问题容易误判为 DeepAI API 中转站不可用。实际上,中转站只是把 Dify 的请求路由到目标模型;如果请求体里包含目标模型不接受的参数,上游会按协议返回 400。对站长来说,关键是通过中转站日志看清楚:Dify 到底发送了 max_tokens,还是已经发送了 max_completion_tokens。
为什么 max_tokens 会变成兼容性问题
OpenAI Chat Completions 的参数说明里,max_tokens 已经被标记为由 max_completion_tokens 替代,并且不兼容 o-series 模型。新一代理性推理模型的输出预算不仅包括最终可见文本,也可能包含 reasoning tokens,因此客户端不能只沿用传统聊天模型的 max_tokens。
{
"model": "gpt-5",
"messages": [
{"role": "user", "content": "写一个 Dify 工作流接入检查清单"}
],
"max_tokens": 1024
}
上面这种请求在部分 reasoning 模型上会被拒绝。更稳的做法是由 Dify 插件根据模型能力或用户配置选择参数名:
{
"model": "gpt-5",
"messages": [
{"role": "user", "content": "写一个 Dify 工作流接入检查清单"}
],
"max_completion_tokens": 1024
}
官方插件里的修复脉络
Dify 官方插件仓库后续出现了几次相关修复。PR #2713 在 2026-03-13 合并,目标就是修复 GPT-5 类模型需要 max_completion_tokens 而不是 max_tokens 的问题。PR #2771 在 2026-03-23 合并,进一步修复了 OpenAI-API-compatible Provider 在凭据校验时仍然错误发送 max_tokens 的问题。
PR #2771 的说明尤其值得关注:当 token_param_name 已经设置为 max_completion_tokens 时,基础校验逻辑仍然会先发送 max_tokens,导致模型添加阶段直接失败;另外某些重试路径还错误地切到了 Responses API,而自定义 OpenAI-compatible endpoint 实际使用的是 Chat Completions API。修复后的方向是:校验和真实推理都使用一致的 client.chat.completions.create(max_completion_tokens=...) 路径。
DeepAI API 中转站场景下怎么排查
如果你在 Dify 中添加 DeepAI API 中转站模型时遇到这个错误,建议按下面顺序排查。不要一上来就换 Key 或换模型,因为这类 400 的核心通常是参数名。
- 确认 Dify 的 Provider 类型是 OpenAI-API-compatible,Base URL 写为
https://api.deepai.wang/v1,不要写到/chat/completions。 - 在 DeepAI API 中转站后台查看失败请求日志,找到请求体里的 token 上限字段。
- 如果模型是 o1、GPT-5 或标记为 reasoning 的模型,优先检查是否仍然发送
max_tokens。 - 升级 Dify OpenAI / OpenAI-API-compatible 官方插件到包含 PR #2713、PR #2771 后续修复的版本。
- 如果插件支持
token_param_name或类似模型参数配置,将该模型显式设置为max_completion_tokens。
推荐配置与验证请求
在 Dify 里配置 DeepAI API 中转站时,基础项应保持简单。复杂兼容性放在模型参数里处理,而不是把接口路径写死。
Provider: OpenAI-API-compatible Base URL: https://api.deepai.wang/v1 API Key: 使用 DeepAI 后台生成的密钥 Model Type: LLM Model Name: 使用中转站后台开放的实际模型 ID Token Parameter: max_completion_tokens
可以用 curl 做一次最小化验证,排除 Dify UI 和插件校验逻辑的干扰:
curl https://api.deepai.wang/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_DEEPAI_KEY" \
-d '{
"model": "your-reasoning-model",
"messages": [
{"role": "user", "content": "用三点说明 Dify 接入 API 中转站的价值"}
],
"max_completion_tokens": 512
}'
如果 curl 使用 max_completion_tokens 能成功,而 Dify 添加模型仍然失败,就说明问题集中在 Dify 插件的凭据校验或参数映射层,而不是 DeepAI API 中转站路由层。
常见坑位
- 凭据校验和真实调用不一致:有些版本在真实调用里改对了参数,但保存模型时的 validate_credentials 仍然发送旧字段。
- 误用 Responses API:OpenAI-API-compatible 中转站通常是 Chat Completions 路径,不要在重试逻辑里突然切到 Responses API。
- 所有模型共用一套参数:普通聊天模型、reasoning 模型、图像模型、Embedding 模型的参数表不应该混用。
- Base URL 过度拼接:Dify 里写
https://api.deepai.wang/v1,让客户端自己拼接/chat/completions。 - 只看前端弹窗:前端只显示 400 时,要到 DeepAI 中转站日志里看完整错误字段
param和code。
API 中转站的使用价值
DeepAI API 中转站在这类问题里不只是“转发请求”。它更像一个可观测的兼容层:你可以看到 Dify 发送了哪个模型、哪个路径、哪个参数名、哪个状态码;也可以把不同客户端的请求并排比较,例如 Dify、Cherry Studio、OpenClaw、n8n 是否都给同一模型发送了相同的 token 字段。
对运营者来说,建议在中转站模型列表里把参数兼容性标注清楚:普通模型使用 max_tokens 或兼容两者;reasoning 模型优先使用 max_completion_tokens;如果某个上游拒绝旧参数,就在接入文档里明确写出 Dify、OpenClaw、n8n 的配置方式。这样用户搜索“Dify max_tokens 400”“GPT-5 max_completion_tokens”“OpenAI Compatible reasoning model”时,能直接找到可执行的解决方案。
参考资料
- Dify Issue #10348:max_tokens unsupported, use max_completion_tokens instead
- Dify Official Plugins Issue #1845:GPT-5 reasoning models validation failed
- Dify Official Plugins PR #2713:GPT-5 like model needs max_completion_tokens
- Dify Official Plugins PR #2771:fix credential validation with max_completion_tokens
- OpenAI Chat Completions API 参数说明
总结
Dify 接入 DeepAI API 中转站时,如果 o1、GPT-5 或其他 reasoning 模型在保存或运行时返回 Unsupported parameter: max_tokens,排查重点不是 Key,而是 token 上限参数名。先用 curl 验证 max_completion_tokens 是否能走通,再升级 Dify 官方插件或显式配置 token_param_name。把 Dify 插件校验、Chat Completions 实际调用和 DeepAI 中转站日志三者对齐后,这类 400 通常就能稳定解决。