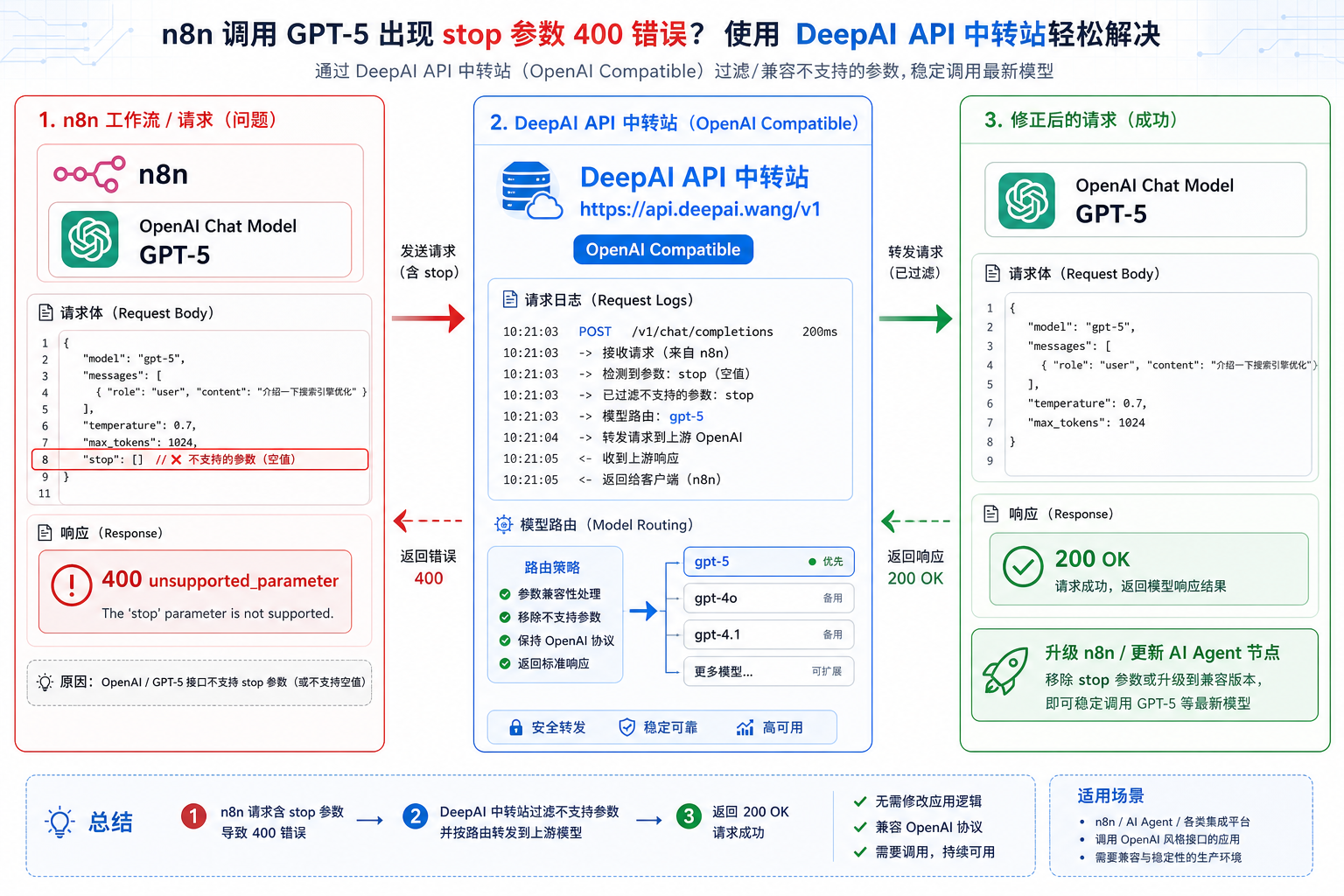
OpenClaw 通过 OpenAI-compatible Provider 流式调用模型时,除了“能不能返回答案”,还要关注 Token 用量是否能被正确记录。对使用 DeepAI API 中转站 的团队来说,Token 统计直接关系到成本控制、额度告警、用户分账和异常排查。如果流式响应里没有 usage 信息,仪表盘就可能显示 0 tokens。
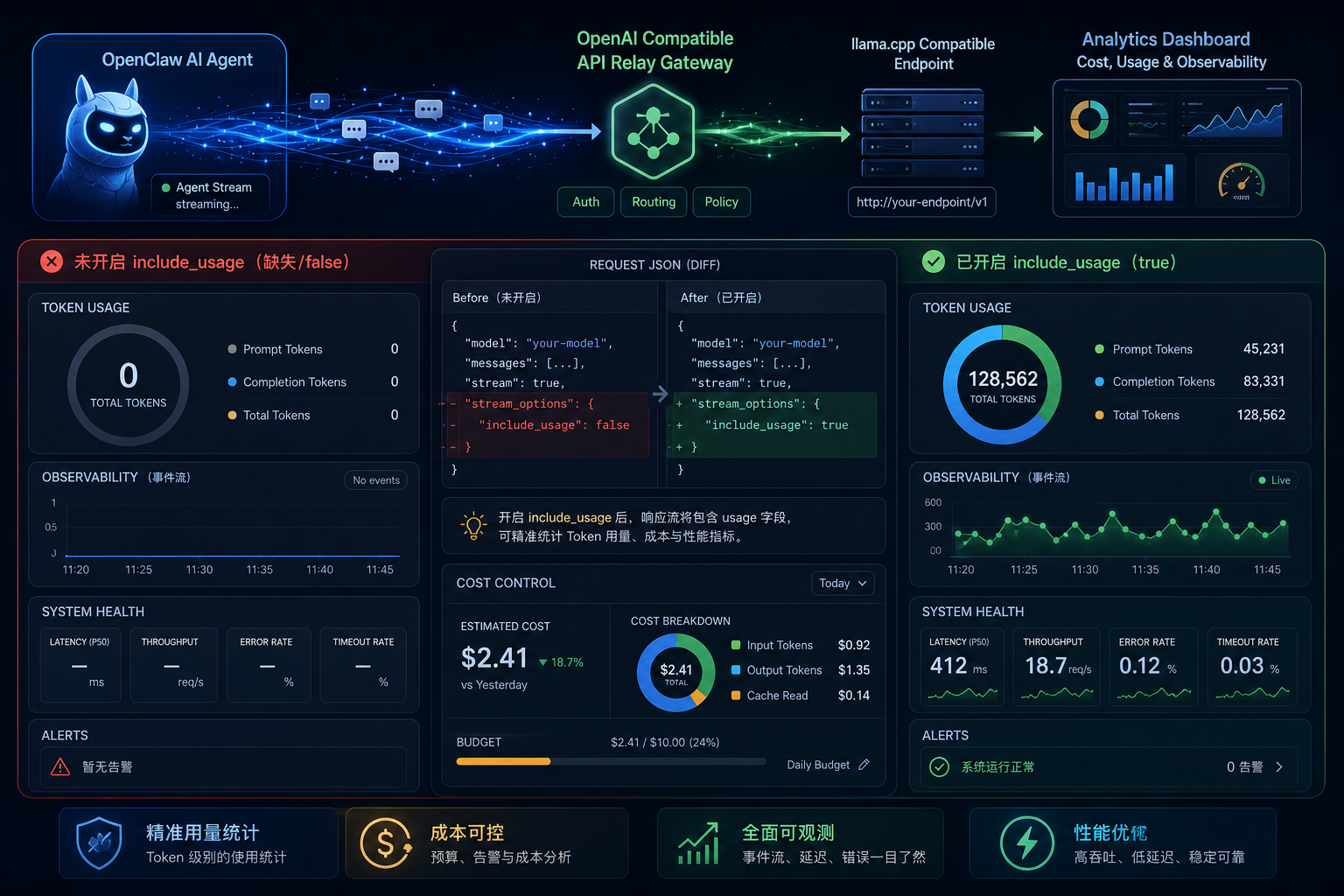
stream_options.include_usage,可能导致 Token 用量、成本和仪表盘数据缺失。GitHub Issue 背景:流式能返回,但 usage 是 0
OpenClaw GitHub 仓库中有一个已关闭且标记为 completed 的 Issue:自定义 OpenAI-compatible Provider 在 embedded session 流式调用时,没有带上 stream_options.include_usage。模型本身可以正常 stream 输出,但 transcript usage 记录为 0,dashboard usage 也显示没有 Token。
Issue 中的场景是 OpenClaw 接 llama.cpp-compatible OpenAI /v1/chat/completions endpoint。代理探针显示:请求没有开启 include_usage,因此没有看到 OpenAI 风格的 usage block。虽然 llama.cpp 侧仍有非零的 prompt 和 predicted timings,但 OpenClaw 的转录和成本面板拿不到标准 usage 数据。
为什么 Token 用量会变成 0
在非流式请求里,模型服务通常会在响应末尾直接返回 usage 字段。但在流式请求中,usage 是否随 SSE 返回,取决于服务端和客户端是否约定开启。OpenAI-compatible 接口常见写法是:
{
"stream": true,
"stream_options": {
"include_usage": true
}
}
如果这段参数没有出现在请求体里,模型仍然可能正常输出文本,但调用方无法拿到标准 usage 块。于是你会看到“答案有了,Token 没有统计”。
DeepAI API 中转站里应该怎么排查
当 OpenClaw 通过 DeepAI API 中转站调用模型,发现用量为 0 时,不要马上判断是计费系统错误。建议按下面顺序排查:
- 确认请求是否是流式调用,即
stream: true。 - 检查请求体里是否包含
stream_options.include_usage: true。 - 查看 DeepAI API 中转站后台是否记录了请求、模型、状态码和用量。
- 如果后台用量缺失,再检查上游模型服务是否支持流式 usage。
- 对比 OpenClaw transcript、DeepAI 日志和上游 gateway 日志,确认是哪一层丢失 usage。
OpenClaw 自定义 Provider 的关键配置
如果你使用自定义 OpenAI-compatible Provider,Base URL 通常类似:
https://api.deepai.wang/v1
重点不是只让模型能返回文本,而是要让 OpenClaw 的 transport 走到支持 usage 的路径。Issue 中提到的修复方向,是让 PI native openai-completions stream 也经过 OpenClaw boundary-aware transport,从而带上 stream_options.include_usage。如果你还在旧版本上,可以先检查是否存在类似 compat 配置:
{
"compat": {
"supportsUsageInStreaming": true
}
}
不过更推荐升级到包含修复的 OpenClaw 版本,而不是长期依赖每个模型都手动加兼容开关。
如何判断是客户端问题还是上游问题
- 请求体没有 include_usage:优先看 OpenClaw transport、embedded session 或 Provider 配置。
- 请求体有 include_usage,但响应无 usage:优先看上游模型服务是否支持流式 usage。
- 上游返回 usage,但中转站无记录:检查中转站解析、日志字段和流式结束块。
- DeepAI 后台有用量,OpenClaw 为 0:检查 OpenClaw transcript usage 写入逻辑。
这个分层很重要。否则你会在客户端、API 中转站和模型服务之间来回猜,花很多时间却没有证据。
为什么 usage 对 Agent 成本控制特别重要
普通聊天一次请求消耗有限,但 Agent 任务可能包含多轮计划、工具调用、上下文压缩、文件分析和重试。如果 usage 统计为 0,团队会失去三个关键能力:预算控制、异常告警和模型选型对比。尤其是自部署或自定义 Provider 场景,表面上“免费本地模型”也可能有 GPU、服务器和排队成本。
使用 DeepAI API 中转站统一接入 OpenClaw 后,可以把不同模型、不同 Key、不同工作流的调用放到同一套日志和成本视图里。前提是客户端和上游服务都能正确返回 usage。
建议的生产检查清单
- 为 OpenClaw 单独创建 DeepAI API Key,便于按 Key 过滤用量。
- 对每个新模型做一次短流式请求,确认 usage 是否非零。
- 保留 request id 或 correlation id,方便对照 OpenClaw、DeepAI 和上游日志。
- 把 0 token 但有输出的请求列为异常,单独告警。
- 升级 OpenClaw 后重新验证 stream_options 和 dashboard usage。
参考资料
- OpenClaw GitHub 仓库
- OpenClaw Issue #78661:custom OpenAI-compatible embedded sessions omit stream_options.include_usage
- OpenClaw 请求丢失历史 messages 排查
- DeepAI API 中转站教程导航
总结
OpenClaw 接入 DeepAI API 中转站时,如果流式调用能正常输出,但 Token 用量显示为 0,优先检查 stream_options.include_usage。这类问题通常不是“模型没计费”,而是客户端、transport 或上游服务没有把 usage 块带回来。把请求体、DeepAI 中转站日志和 OpenClaw dashboard 对齐,才能让 Agent 的成本、性能和稳定性真正可观测。