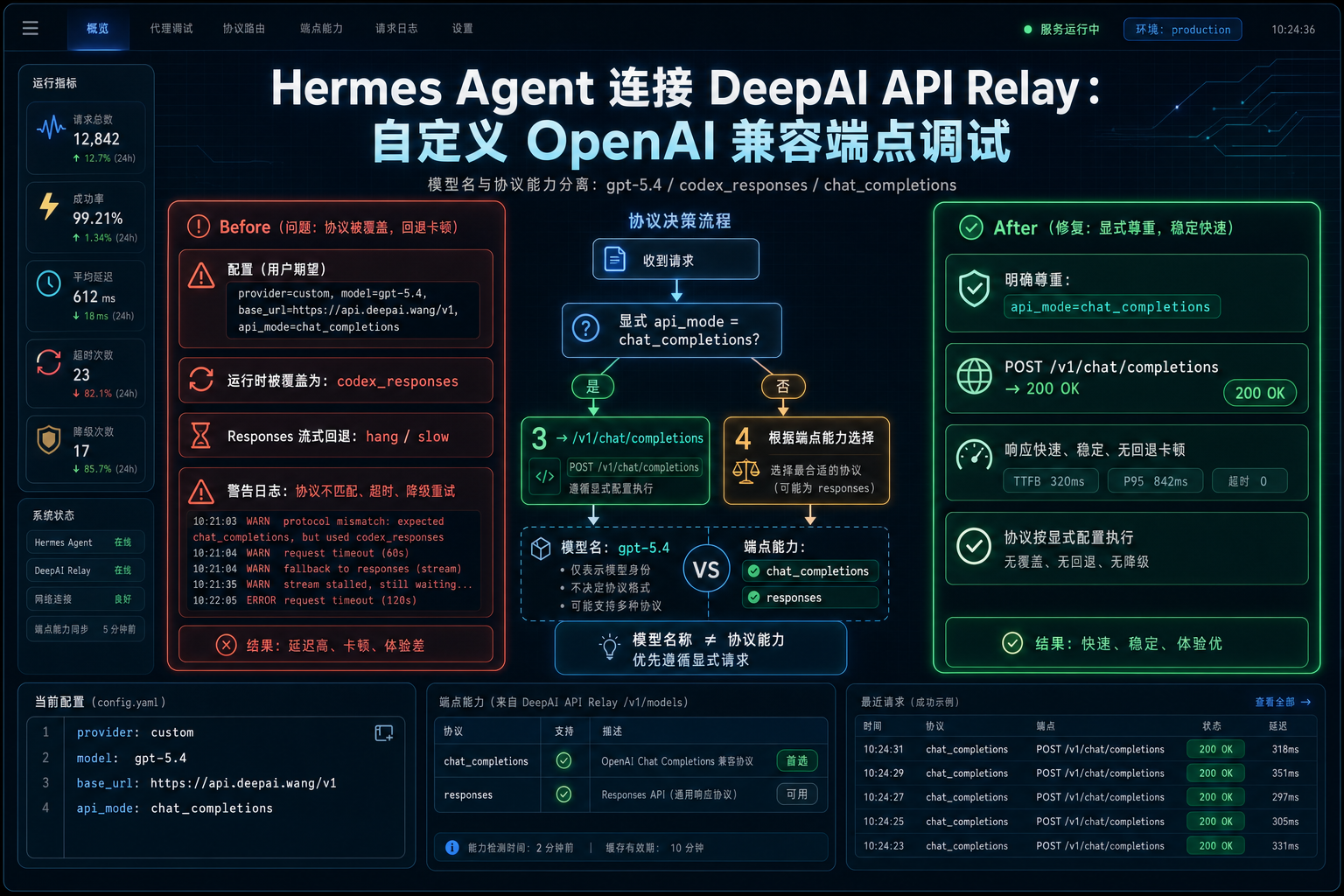
Hermes Agent 通过自定义 OpenAI-compatible endpoint 接入 DeepAI API 中转站 时,很多人会把模型名保持为上游风格,例如 gpt-5.4、gpt-5-proxy 或其他以 gpt-5 开头的路由名。但模型名只是路由标识,不一定代表这个自定义端点支持 Responses API。如果客户端仅凭模型名前缀强行切换协议,就可能把本来能正常工作的 /v1/chat/completions 链路变成慢请求或卡住。
GitHub Issue 背景:显式 chat_completions 被覆盖
这个问题来自 Hermes Agent Issue #10473。用户使用 provider=custom、模型名 gpt-5.4、自定义 OpenAI-compatible proxy,并在创建 AIAgent 时显式传入 api_mode="chat_completions"。结果打印 agent.api_mode 时,实际值却变成了 codex_responses。
agent = AIAgent(
model="gpt-5.4",
provider="custom",
base_url="https://your-openai-compatible-proxy/v1",
api_key="...",
api_mode="chat_completions",
)
print(agent.api_mode)
# actual: codex_responses
# expected: chat_completions
同一个端点直接请求 /v1/chat/completions 可以在数秒内返回,但 Hermes 运行时走 codex_responses 后可能非常慢,甚至出现 Responses create(stream=True) fallback did not emit a terminal response 之类日志。这说明 Key、Base URL、模型名本身未必有问题,真正的问题是协议选择被运行时覆盖。
根因:模型名前缀触发 Responses API 自动升级
Issue 中定位到的逻辑是:Hermes 在初始化后,如果当前是 chat_completions,并且判断模型需要 Responses API,就会把 api_mode 改成 codex_responses。其中 _model_requires_responses_api() 会对以 gpt-5 开头的模型返回 true。问题在于,这个判断没有充分区分 direct OpenAI endpoint 和 generic custom proxy。
换句话说,Hermes 把“模型名看起来像 GPT-5”当成了“这个自定义端点必须走 Responses API”。但在 DeepAI API 中转站这类 OpenAI-compatible 代理里,gpt-5.4 可能只是一个路由名,真实可用协议仍然是 /v1/chat/completions。
DeepAI API 中转站场景下怎么判断
- 先用 curl 或 Postman 直接请求
https://api.deepai.wang/v1/chat/completions,确认同一模型能快速返回。 - 在 Hermes 配置里显式设置
provider=custom、base_url=https://api.deepai.wang/v1、api_mode=chat_completions。 - 启动后打印或查看运行时
api_mode,确认是否被改成codex_responses。 - 查看 DeepAI 中转站日志:请求路径到底是
/v1/chat/completions,还是 Responses 风格接口。 - 如果被覆盖,优先升级 Hermes 到包含修复的版本;临时方案是改用不会触发自动升级的模型别名,或明确使用支持 Responses API 的端点。
为什么不要只根据模型名决定协议
API 中转站里,模型名通常承担三种含义:展示名称、路由 ID、上游模型标识。它不一定等于协议能力。比如同一个 gpt-5.4 路由名,可能背后是兼容 Chat Completions 的代理,也可能是支持 Responses API 的直连服务。协议选择应该由端点能力、用户显式配置和 provider 类型共同决定。
更稳的逻辑是:
- 用户显式设置
chat_completions时,custom provider 应优先尊重。 - 只有 direct OpenAI、Codex-style 或已知需要 Responses API 的 endpoint 才自动升级。
- 如果要自动检测,应先探测端点能力,而不是只看模型名。
- 中转站后台应记录请求路径和协议类型,便于定位。
常见误区
- 把慢响应当成模型慢:同一模型直连
/chat/completions很快,但 Hermes 走 Responses fallback 很慢,说明协议可能错了。 - 只检查 Key 和 Base URL:鉴权和路径都正确时,仍可能被客户端改协议。
- 用 gpt-5 前缀做代理别名:如果客户端有前缀规则,别名可能触发不期望的特殊逻辑。
- 忽略运行时配置:配置文件写的是
chat_completions,运行时对象未必仍是这个值。 - 中转站不记录路径:没有请求路径日志,就很难判断实际走了哪个协议。
给 DeepAI 中转站用户的建议
如果你的目标是让 Hermes Agent 稳定接入 DeepAI API 中转站,建议为不同协议能力的模型使用清晰别名。例如,明确支持 Chat Completions 的模型可以使用不触发特殊前缀规则的内部别名;支持 Responses API 的模型再单独标识。这样既能避免客户端误判,也方便后台按协议分组统计成功率和延迟。
同时,在中转站日志里记录三项信息:客户端传入的 model、最终路由的上游模型、实际请求路径。只要看到 Hermes 明明配置了 chat_completions,但后台没有 /v1/chat/completions 请求,就可以迅速定位到客户端协议选择层。
上线前验证清单
- 手动调用
/v1/chat/completions,记录基础延迟和返回内容。 - 用 Hermes 创建最小
AIAgent,打印实际api_mode。 - 比较同一 prompt 在 curl 和 Hermes 中的耗时。
- 检查 DeepAI 中转站日志中的请求路径和 model 字段。
- 对 gpt-5 前缀模型、非 gpt-5 别名模型分别做回归测试。
参考资料
- Hermes Agent Issue #10473:custom GPT-5 endpoint forced to codex_responses
- Hermes Agent 自定义端点多模型被锁定排查
- Hermes Agent 自定义 Provider auxiliary fallback 排查
- DeepAI API 中转站教程导航
总结
Hermes Agent 接入 DeepAI API 中转站时,如果自定义 gpt-5.x 模型明明能通过 /v1/chat/completions 快速返回,却在 Hermes 里变慢或卡住,重点检查运行时 api_mode 是否被强制改成 codex_responses。对 custom OpenAI-compatible endpoint,协议选择应尊重显式 chat_completions 配置和端点能力,而不是只靠模型名前缀判断。把模型别名、协议能力和中转站日志对齐,才能让代理模型稳定服务 Agent 工作流。