Cherry Studio 接入 DeepAI API 中转站 时,除了普通聊天和图片生成,很多用户还会测试 PDF、文档和多模态附件。PDF 这类二进制文件最容易踩的坑,不是模型不能读,而是客户端、中转站或后端服务对 file_data 的 Base64 格式理解不一致。
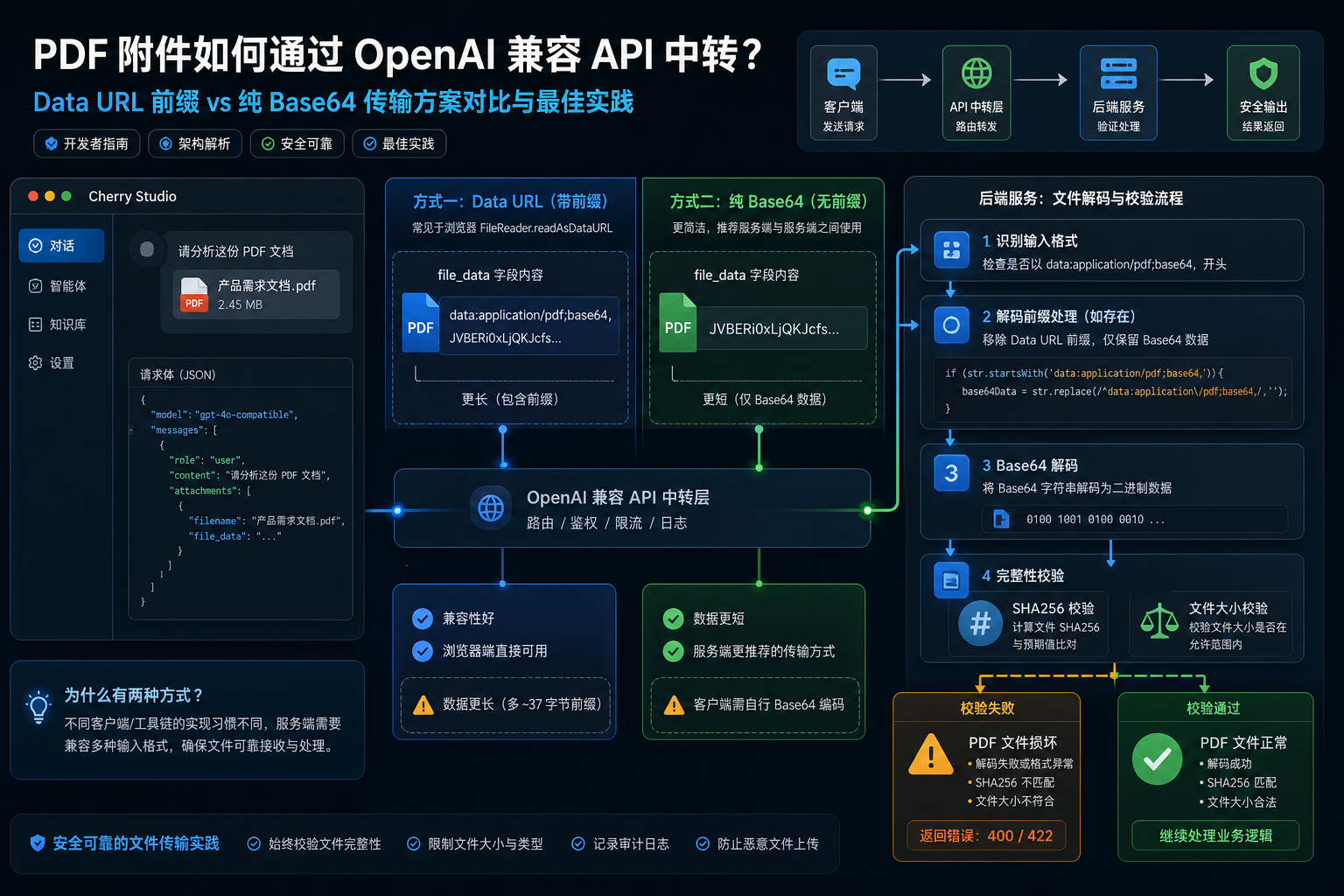
GitHub Issue 背景:看似 Base64 变长,实际是服务端没剥前缀
Cherry Studio GitHub 仓库中有一个已关闭且标记为 completed 的 Issue:用户通过 OpenAI-compatible API 发送 PDF,发现服务端收到的 Base64 比正确值多出 28 个字符,解码后的 PDF 多出字节,SHA256 也和原始文件不一致。最初怀疑是 Cherry Studio 以文本模式读取 PDF,导致二进制内容损坏。
但最终结论是:问题在服务端。Cherry Studio 发送的是 Data URL,例如 data:application/pdf;base64,...,而后端直接把整个字符串传给 Python 的 base64.b64decode(),没有先去掉前缀。由于部分解码器会静默丢弃非 Base64 字符,结果造成二进制偏移和 PDF 损坏。
Data URL 和纯 Base64 有什么区别
处理 PDF 附件时,常见输入有两种格式:
- Data URL:
data:application/pdf;base64,JVBERi0x...,包含 MIME 类型和前缀,浏览器 FileReader 常见。 - 纯 Base64:
JVBERi0x...,只包含文件编码数据,更适合服务端存储和解码。
如果 OpenAI-compatible 协议字段要求纯 file_data,服务端就应该在收到 Data URL 时先识别并剥离前缀;如果协议允许 Data URL,也要在解码前做显式解析,而不是把整段字符串直接当 Base64。
DeepAI API 中转站处理 PDF 的推荐流程
如果你在 DeepAI API 中转站或自建网关里处理 Cherry Studio、Claude Desktop、Open WebUI 等客户端传来的 PDF,建议按以下流程做:
- 识别
file_data是否以data:开头。 - 如果是 Data URL,按第一个逗号拆分,只保留逗号后的 Base64 数据。
- 严格 Base64 解码,避免静默忽略非法字符。
- 校验文件头是否为 PDF,例如
%PDF-。 - 记录文件大小、MIME 类型和 SHA256,便于排查损坏问题。
Python 服务端示例
import base64
import hashlib
def decode_file_data(file_data: str) -> bytes:
if file_data.startswith("data:"):
header, file_data = file_data.split(",", 1)
# header 示例:data:application/pdf;base64
raw = base64.b64decode(file_data, validate=True)
if not raw.startswith(b"%PDF-"):
raise ValueError("decoded file is not a valid PDF")
sha256 = hashlib.sha256(raw).hexdigest()
print("pdf_bytes=", len(raw), "sha256=", sha256)
return raw
关键点是 validate=True。它能让错误更早暴露,而不是让解码器悄悄吞掉非法字符,最后得到一个看似存在但内容已损坏的 PDF。
Node.js 服务端示例
function decodeFileData(fileData) {
let base64 = fileData;
if (base64.startsWith("data:")) {
const comma = base64.indexOf(",");
if (comma === -1) throw new Error("Invalid Data URL");
base64 = base64.slice(comma + 1);
}
const buffer = Buffer.from(base64, "base64");
if (!buffer.subarray(0, 5).equals(Buffer.from("%PDF-"))) {
throw new Error("Decoded file is not a PDF");
}
return buffer;
}
Node.js 的 Buffer.from(..., "base64") 也要配合额外校验。不要只看“能解码”,还要看文件头、大小、Hash 和模型端能否真正读取。
如何判断问题在客户端还是服务端
- 同一 PDF 用 Python 正确编码后可用:说明模型和中转站主链路大概率没问题。
- Cherry Studio 发送的是 Data URL:服务端应支持或转换 Data URL。
- 解码后文件大小多出字节:重点检查是否把前缀一起解码了。
- SHA256 不一致:说明文件已经损坏,不能继续交给模型处理。
- 模型提示无法读取 PDF:先查文件完整性,再查模型能力。
API 中转站为什么要兼容两种格式
不同客户端的实现习惯不一样。浏览器和 Electron 客户端常用 Data URL,因为它天然包含 MIME 类型;服务端和 SDK 更常用纯 Base64,因为它更短、更容易校验。DeepAI API 中转站这类统一入口面对的是多种客户端,最好能兼容两种输入格式,并在日志里记录最终解析后的文件类型和大小。
这样用户从 Cherry Studio、Open WebUI、Dify、n8n 或自写脚本传 PDF 时,就不会因为格式差异出现“文件上传成功但模型读不了”的问题。
安全与限制建议
- 限制 PDF 文件大小,避免超大文件拖垮请求和上下文。
- 校验 MIME 类型和文件头,不要只相信客户端传来的 filename。
- 对上传文件做临时存储和过期清理。
- 日志里记录 Hash 和大小,但不要记录完整 Base64 内容。
- 对异常 Base64 返回明确错误,例如 400 或 422,而不是把损坏文件继续传给模型。
参考资料
- Cherry Studio GitHub 仓库
- Cherry Studio Issue #14812:PDF file_data Base64 与 Data URL 前缀问题
- Cherry Studio Base URL 与 /v1/messages 404 排查
- DeepAI API 中转站教程导航
总结
Cherry Studio 接入 DeepAI API 中转站处理 PDF 时,文件损坏不一定是客户端编码错误,也不一定是模型不支持 PDF。很多时候,问题只是服务端把 Data URL 前缀当成纯 Base64 一起解码了。正确做法是先识别格式、剥离前缀、严格解码,再用文件头、大小和 SHA256 校验完整性。把这条链路做好,PDF、多模态和文件类 OpenAI-compatible API 才能稳定运行。