n8n 的 RAG 工作流里,Embeddings OpenAI 节点经常接在 Postgres PGVector Store、Supabase Vector Store 或其他向量库前面。通过 DeepAI API 中转站 接入 OpenAI-compatible Embedding API 时,最危险的问题不是直接报错,而是请求返回 200,但 embedding 数组全是 0。这样工作流表面成功,实际向量检索完全失效。
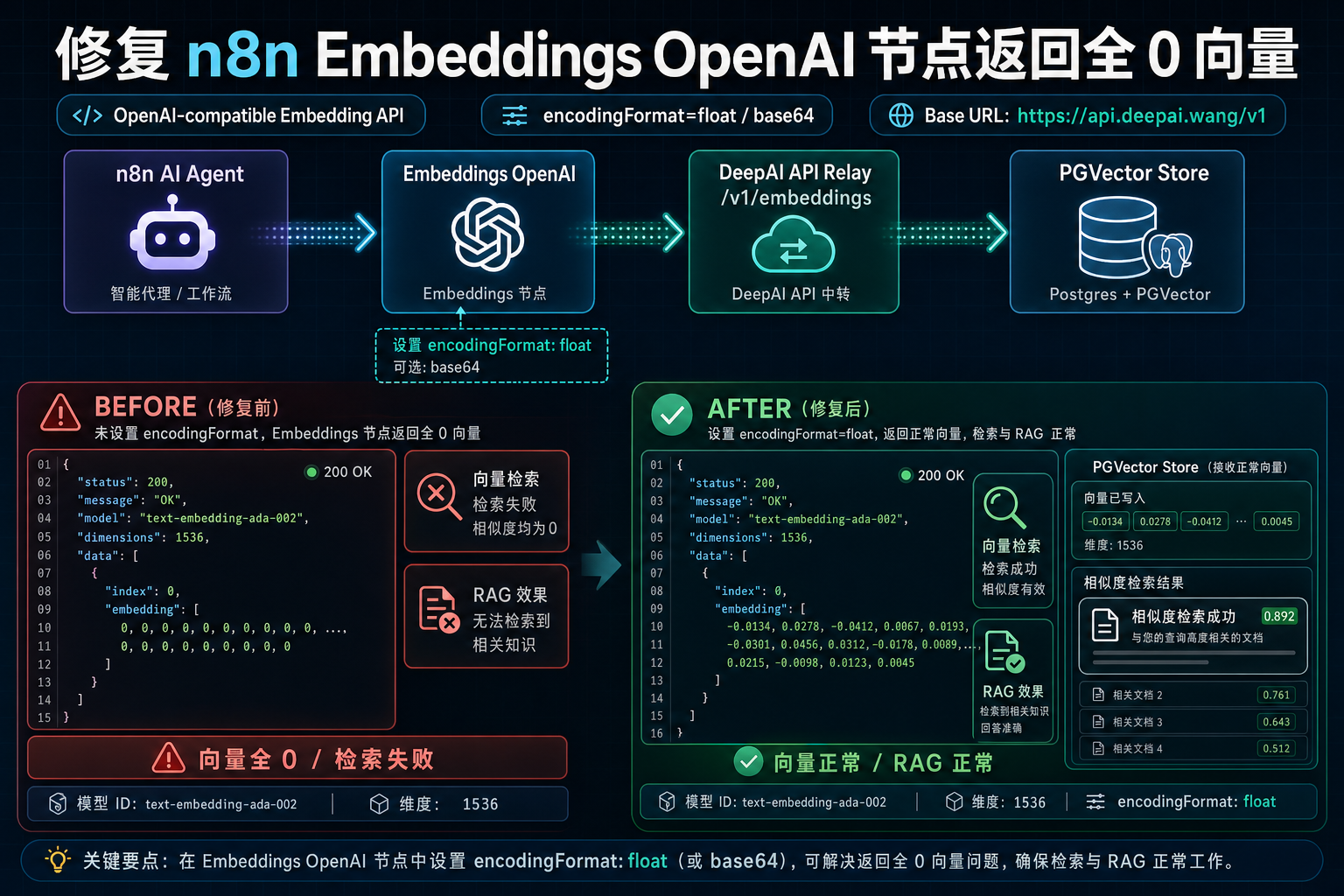
encodingFormat 是关键排查点。GitHub Issue 背景:curl 正常,n8n 节点却返回全 0
这个问题来自 n8n Issue #16985。用户在 n8n 1.98.1 Docker 环境中,使用 AI Agent + Postgres PGVector Store,并把 Embeddings OpenAI 节点指向 LM Studio 的 OpenAI-compatible Embedding API。手动 curl 测试接口能返回正常向量,但 n8n 节点输出的 embedding 数组却全是 0。
用户尝试了 text-embedding-qwen3-embedding-8b、nomic-embed-text、mxbai-embed 等多个模型,现象一致。这说明问题不是单个模型坏了,而更可能是客户端库和兼容 API 在响应编码格式上存在不匹配。
已修复线索:PR #20877 增加 encodingFormat 参数
后续 n8n PR #20877 修复了这个问题:在 Embeddings OpenAI 节点中新增可选 encodingFormat 参数,选项包括 Float 和 Base64,并升级 @langchain/openai 到支持该参数的版本。PR 说明里明确提到,LM Studio 和类似 OpenAI-compatible API 需要显式设置 encoding_format,否则可能返回全 0 向量。
该修复已在 n8n 1.117.0 发布。也就是说,如果你还在使用旧版本 n8n,遇到全 0 向量时,首先应升级到包含 encodingFormat 的版本。
DeepAI API 中转站场景下怎么配置
使用 DeepAI API 中转站时,n8n Embeddings OpenAI 凭据和节点建议按以下原则配置:
- Base URL:填写
https://api.deepai.wang/v1,不要写到/embeddings。 - API Key:使用 DeepAI API 中转站分配的 Key,不要混用上游供应商 Key。
- Model:填写中转站后台支持的 Embedding 模型 ID,不能填聊天模型。
- encodingFormat:如果兼容接口返回全 0,优先设置为
float;必要时再测试base64。
一个正常的 OpenAI-compatible Embedding 请求大致应该返回非零浮点数组:
{
"object": "list",
"data": [
{
"index": 0,
"embedding": [0.0149, -0.0221, 0.0037, ...]
}
],
"model": "your-embedding-model",
"usage": {
"prompt_tokens": 12,
"total_tokens": 12
}
}
排查步骤:不要只看状态码 200
- 先用 curl 或 Postman 直接请求 DeepAI API 中转站的
/v1/embeddings,确认返回非零向量。 - 在 n8n 中使用同一个 Base URL、Key 和模型 ID 配置 Embeddings OpenAI 节点。
- 执行一个短文本 embedding 测试,检查节点输出数组是否全 0。
- 如果全 0,升级到 n8n 1.117.0 或更新版本,并把
encodingFormat设置为 Float。 - 再次写入 PGVector,确认相似度检索结果不再全部相同或全部为 0。
这里最容易踩坑的是:HTTP 200 只能说明接口成功返回,不能说明向量可用。向量是否可用,要看数组是否非零、维度是否正确、写入向量库后相似度分数是否有区分度。
为什么全 0 向量会破坏 RAG
RAG 检索依赖“语义相似度”。如果所有文档都被写成全 0 向量,查询向量也是全 0,向量库就无法判断哪段文本更相关。表现可能是:
- PGVector / Supabase Vector Store 返回空结果。
- 每次返回的文档都差不多,和问题无关。
- 相似度分数全部相同、全部为 0,或排序没有语义意义。
- AI Agent 看起来能聊天,但知识库回答完全不准。
所以,Embedding 接入验证不能只看“节点不报错”。要把返回值抽样打印出来,确认至少前几十个维度不是全 0。
DeepAI 中转站后台应该看哪些指标
- 请求路径:应为
/v1/embeddings,不是/v1/chat/completions。 - 模型 ID:确认路由到 Embedding 模型,而不是聊天模型。
- 状态码:401 看 Key,404 看路径和模型名,200 后继续看向量内容。
- 维度:同一个向量库集合内必须保持一致。
- 用量:Embedding 请求通常 token 量小但调用频繁,适合单独统计成本。
常见坑位
- 只测 Chat,不测 Embeddings:聊天模型成功不代表 Embedding 链路成功。
- Base URL 写到接口路径:n8n 会自己拼接
/embeddings。 - 旧版 n8n 没有 encodingFormat:升级到 1.117.0 或更新版本。
- 向量维度混用:更换 Embedding 模型后,旧向量库可能需要重建。
- 误把全 0 当成空知识库:文档可能已经写入,但向量没有语义信息。
上线前验证清单
- 使用 DeepAI API 中转站手动请求
/v1/embeddings,保存一组非零向量样本。 - 在 n8n 节点里设置同样模型,并开启
encodingFormat: float。 - 写入三段语义不同的文本到 PGVector。
- 用一个相关问题检索,确认相似度分数有明显区分。
- 检查 DeepAI 中转站日志,确认每次入库和查询都产生 Embedding 调用。
参考资料
- n8n Issue #16985:Embeddings OpenAI node returns zero values with LM Studio API
- n8n PR #20877:Add encodingFormat parameter to Embeddings OpenAI node
- n8n 1.117.0 Release
- DeepAI API 中转站教程导航
总结
n8n 接入 DeepAI API 中转站做 RAG 时,如果 Embeddings OpenAI 节点返回全 0 向量,优先检查 n8n 版本和 encodingFormat 设置。升级到包含 PR #20877 的版本后,将兼容 Embedding API 的编码格式显式设为 Float,通常就能恢复非零向量。真正的验证标准不是“请求 200”,而是向量非零、维度一致、PGVector 相似度检索有区分度。