OpenClaw 这类 Agent 工具的“记忆”能力,通常离不开 Embedding 和向量检索。聊天模型负责推理,Embedding 模型负责把历史片段、用户偏好、任务线索变成可检索向量。如果你通过 DeepAI API 中转站 统一接入 OpenAI-compatible 模型,记忆插件是否支持自定义 baseUrl、模型名和向量维度,就会直接影响 auto-recall / auto-capture 能不能稳定工作。
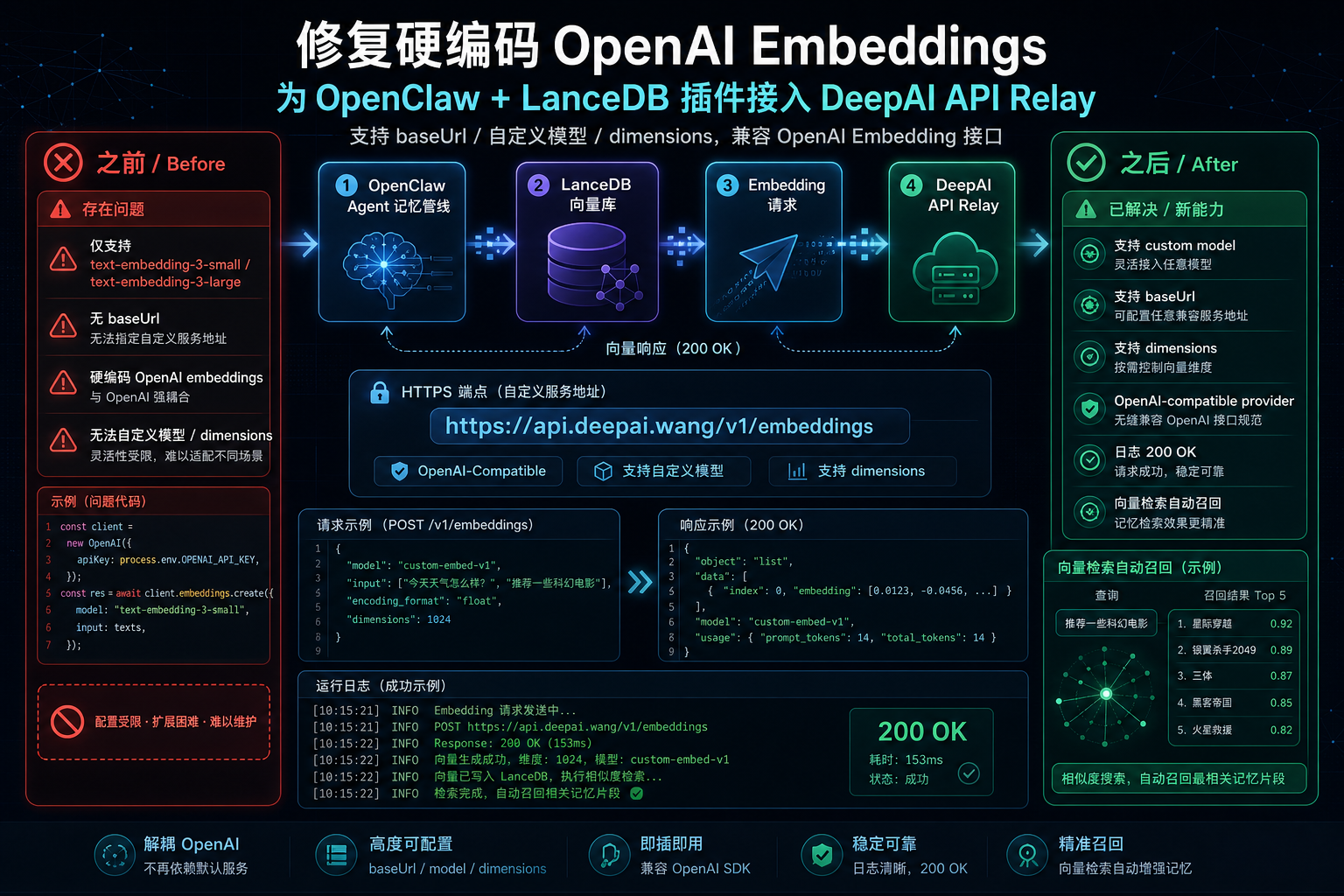
GitHub Issue 背景:memory-lancedb 曾经锁死官方 OpenAI Embeddings
这个问题来自 OpenClaw Issue #8118。Issue 描述中提到,memory-lancedb 插件当时只支持 text-embedding-3-small 和 text-embedding-3-large,配置 schema 里把模型名写成了固定枚举;初始化 OpenAI 客户端时也只传 apiKey,没有开放 baseUrl。
model: {
type: "string",
enum: ["text-embedding-3-small", "text-embedding-3-large"]
}
this.client = new OpenAI({ apiKey }) // no baseUrl
这会让用户陷入两难:核心 memory 系统已经能配置 OpenAI-compatible Embedding Provider,但 memory-lancedb 插件提供的自动召回和自动捕获功能,却仍然被官方 OpenAI Embedding 接口绑定。
已解决线索:#17874 增加 custom endpoint 和 dimensions 支持
Issue 后续由维护者关闭,并说明已通过合并的 #17874 实现:为 memory-lancedb 增加自定义 OpenAI-compatible endpoint 和 dimensions 支持。也就是说,最新实现已经朝着“Embedding Provider 与聊天 Provider 一样可配置”的方向修复。
对 DeepAI API 中转站用户来说,这个修复非常关键:Embedding 请求可以走 https://api.deepai.wang/v1/embeddings,模型名不再只能是官方枚举,也可以使用中转站后台开放的自定义 Embedding 模型。
推荐配置思路:Base URL、模型名、维度三件事分开确认
接入 OpenAI-compatible Embedding Provider 时,建议把配置拆成三层:
- Base URL:统一写到
https://api.deepai.wang/v1,让客户端自己拼接/embeddings。 - Embedding 模型名:使用 DeepAI API 中转站后台实际支持的 model id,不要混用展示名。
- dimensions:如果模型支持自定义维度,确保 LanceDB 表结构、历史向量和新请求维度一致。
一个概念化配置可以类似这样:
{
"memorySearch": {
"provider": "openai",
"remote": {
"baseUrl": "https://api.deepai.wang/v1",
"apiKey": "YOUR_DEEPAI_API_KEY"
},
"model": "your-embedding-model",
"dimensions": 1024
}
}
实际字段名称要以你当前 OpenClaw 版本和插件文档为准;核心原则是:Embedding 不是聊天模型的附属配置,它需要独立验证。
DeepAI API 中转站场景下怎么排查
- 先确认 OpenClaw 聊天模型是否能通过 DeepAI API 中转站正常请求,这只验证 chat 链路。
- 再单独测试 Embedding 接口,确认
/v1/embeddings返回data[].embedding。 - 检查 OpenClaw / memory-lancedb 配置里是否能填写
baseUrl和自定义模型名。 - 如果报模型不在枚举中,说明还在使用旧插件或旧配置 schema。
- 如果写入 LanceDB 失败,重点检查 embedding 向量维度是否和表中历史数据一致。
常见坑位
- 聊天可用但记忆不可用:Chat Completions 和 Embeddings 是两条接口链路,必须分别测试。
- Base URL 写太深:不要把 Base URL 写成
/v1/embeddings,否则客户端可能重复拼接路径。 - 模型名被枚举限制:旧版本只允许官方模型名时,需要升级到包含自定义 Provider 修复的版本。
- 维度不一致:同一个 LanceDB 表里混入不同维度的向量,检索和写入都可能失败。
- 误用聊天模型做 embedding:Embedding 请求必须路由到 Embedding 模型,不要用普通对话模型 ID。
为什么这对 Agent 记忆很重要
Agent 记忆的质量很大程度取决于向量检索质量。Embedding 模型、向量维度、分段策略和向量库写入都会影响召回。如果 memory-lancedb 只能使用固定官方模型,站长就很难基于成本、隐私、地域和模型效果做优化。接入 DeepAI API 中转站后,可以统一管理 Embedding 模型、Key、日志和额度,把记忆链路纳入同一套可观测体系。
更重要的是,DeepAI 中转站后台日志可以告诉你:Embedding 请求是否真的发出、用了哪个模型、返回维度是多少、耗时和状态码如何。这些信息比单纯看 OpenClaw 前端“记忆没有召回”更容易定位问题。
上线前验证清单
- 用一个短文本手动调用 DeepAI Embeddings 接口,确认返回向量数组。
- 记录 embedding 维度,并确认 LanceDB 表使用相同维度。
- 让 OpenClaw 写入一条记忆,检查中转站日志中是否出现 Embedding 请求。
- 用相关问题触发 auto-recall,确认检索结果能返回到 Agent 上下文。
- 更换模型或 dimensions 前,规划是否需要重建向量库。
参考资料
- OpenClaw Issue #8118:memory-lancedb support custom embedding providers
- OpenClaw 请求丢失历史 messages 排查
- OpenClaw stream_options include_usage 与 token 统计排查
- DeepAI API 中转站教程导航
总结
OpenClaw 接入 DeepAI API 中转站时,聊天链路成功不代表 memory-lancedb 记忆链路也成功。遇到自定义 Embedding Provider 不可用、模型名被限制或 LanceDB 写入失败时,重点检查插件版本是否支持 baseUrl、自定义模型名和 dimensions。把 Embedding 请求也纳入 DeepAI API 中转站的统一日志和路由管理,才能让 Agent 的长期记忆、自动召回和向量检索真正稳定起来。